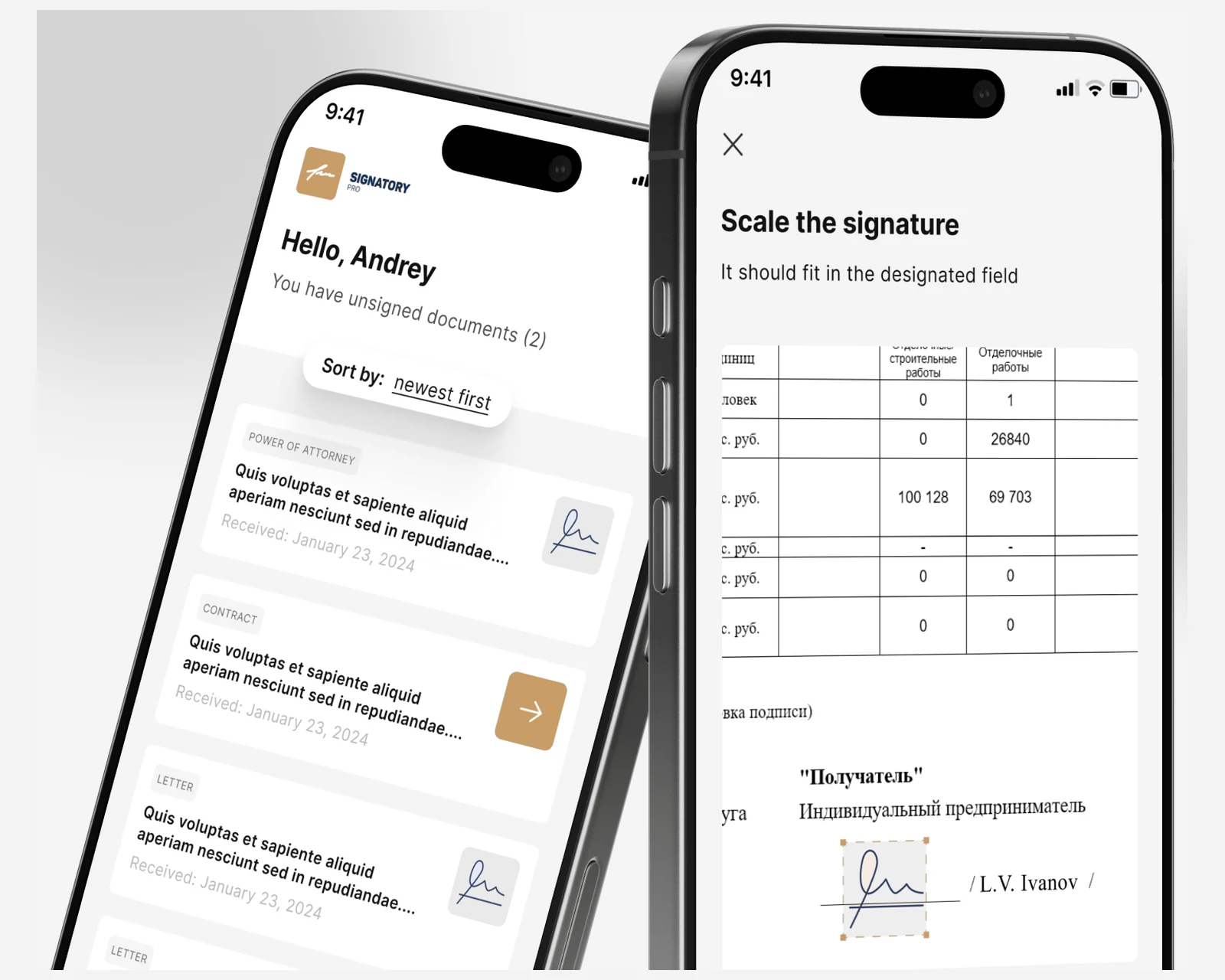
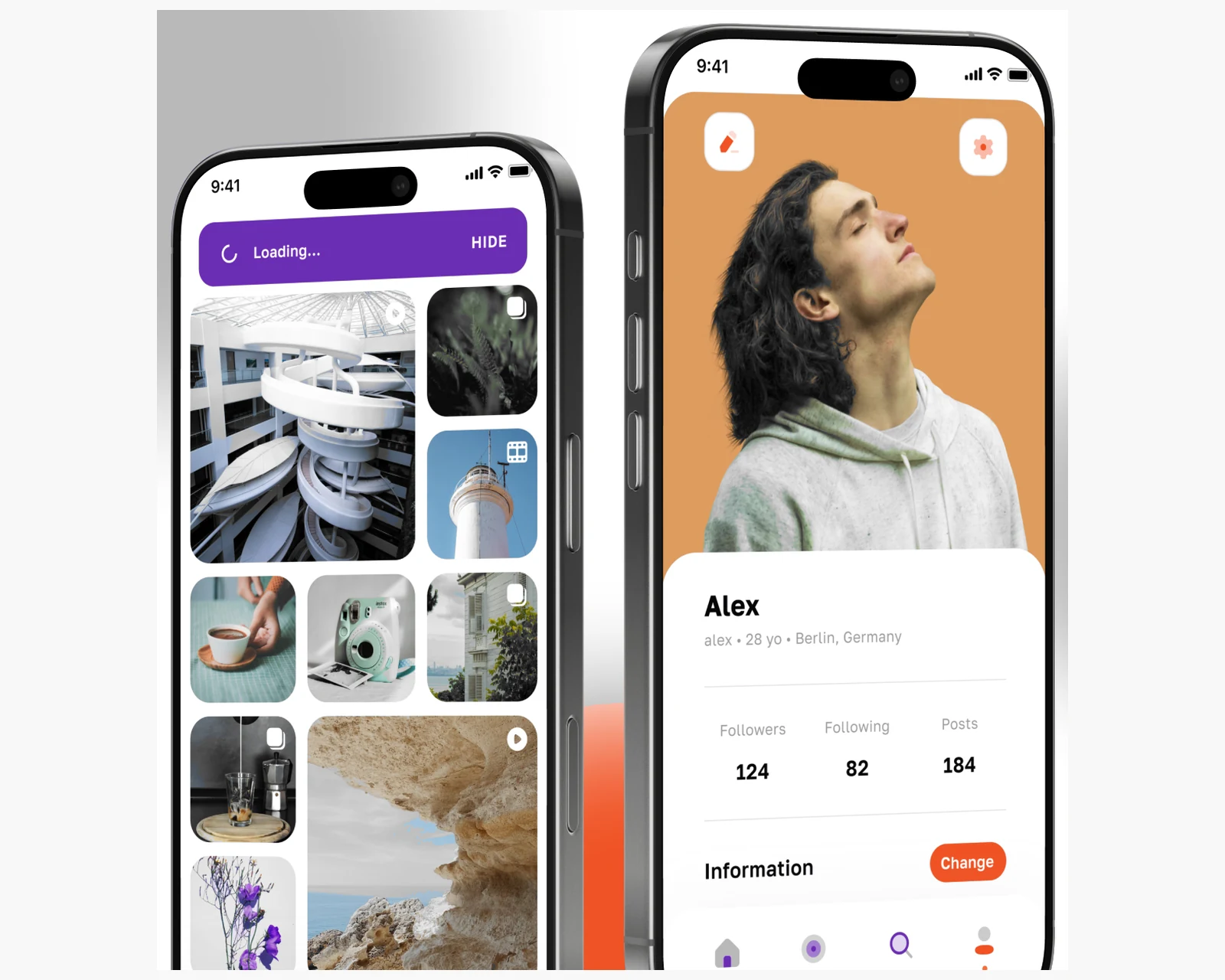
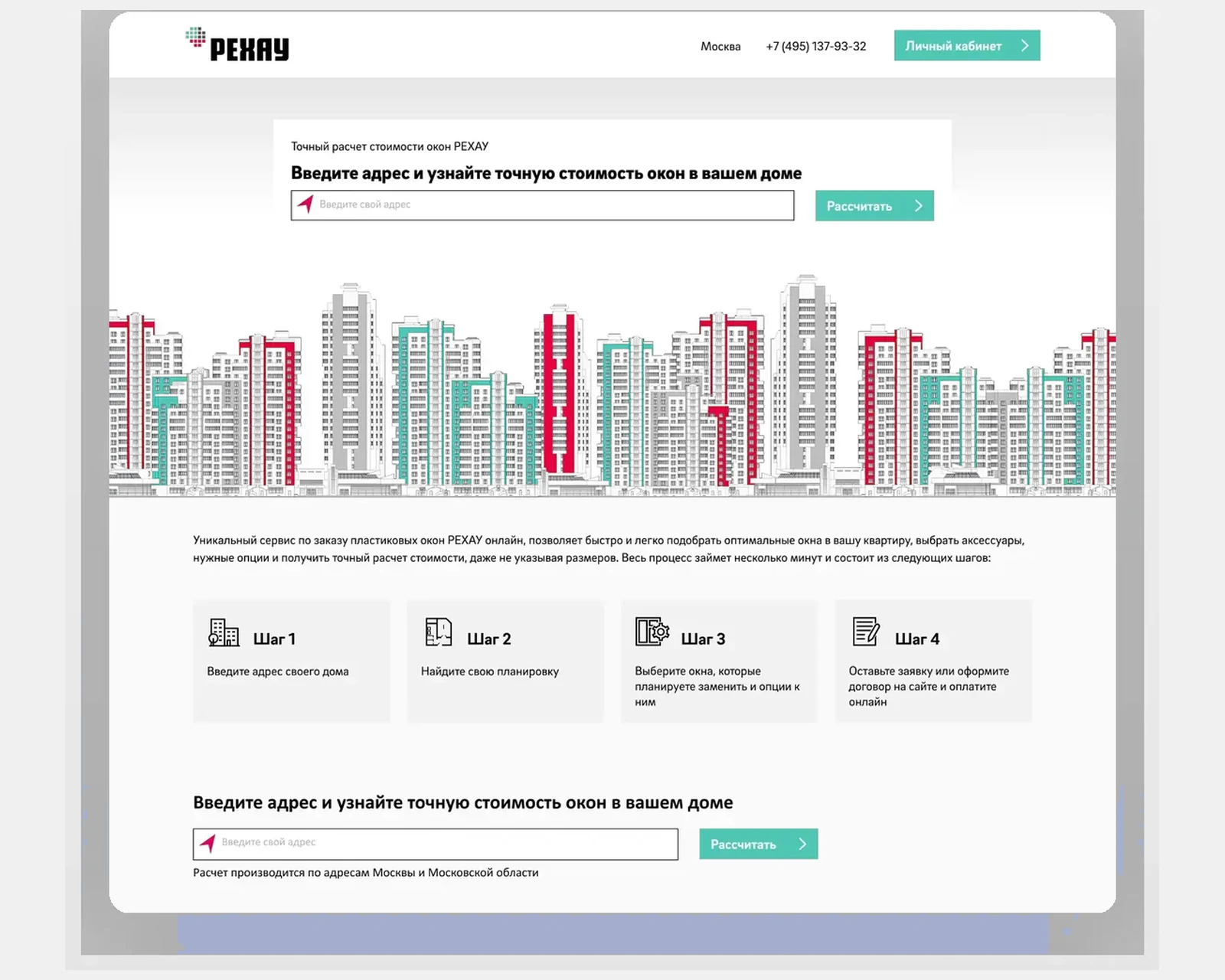
Data curation & labelling pipelines
Golden-set construction, labelling rubrics, inter-annotator agreement tracking, PII redaction with Presidio, synthetic data generation with frontier models, and deduplication. The labelling pipeline lives in your cloud, not ours.