Consumer lag accumulation
Slow consumers accumulate unbounded lag silently. We wire Prometheus lag exporter, set lag alerts and implement KEDA consumer autoscaling.
KRaft Schema Registry MSK SOC 2-ready
Kafka underpins our highest-throughput event pipelines — Scooter Sharing's ride telemetry stream processing thousands of IoT events per second, xRouten's logistics event bus, Loan Conveyor's audit event sourcing. MSK on AWS, Confluent Cloud and self-hosted KRaft clusters — all in production for us.

We deliver Kafka engineering for fintech event sourcing, IoT and telematics ingest, microservice event buses, and change data capture pipelines connecting databases to downstream consumers. Schema Registry keeps producer-consumer contracts safe across deployments. Kafka Connect and Debezium move data between Kafka and databases without custom pipelines. KRaft eliminates ZooKeeper for new clusters.
Challenges
Slow consumers accumulate unbounded lag silently. We wire Prometheus lag exporter, set lag alerts and implement KEDA consumer autoscaling.
Producer schema changes break consumers on old versions. We enforce Schema Registry BACKWARD compatibility checks in CI.
Too few partitions cap consumer parallelism and create hotspots. We size partitions to maximum desired consumer concurrency at design time.
Frequent consumer restarts trigger rebalancing that stalls processing for seconds. We tune session.timeout.ms, use cooperative sticky rebalancing and minimise unnecessary consumer restarts.
At-least-once with duplicate handling is often safer than transactional exactly-once. We design idempotent consumers with deduplication tables before reaching for Kafka transactions.
ZooKeeper dependency adds a separate quorum to operate. We migrate to KRaft mode for new clusters and plan ZooKeeper removal for existing ones.
Solutions
Domain events published by producers, consumed by multiple downstream services — with DLQ, retry and event schema contracts.
Debezium Kafka Connect capturing PostgreSQL or MySQL WAL events as Kafka topics — for cache invalidation, search index sync and audit.
High-frequency sensor streams partitioned by device ID, consumed by stream processors and landed in time-series databases.
Immutable event logs for financial transactions — compacted topics, exactly-once producers and audit consumer groups.
Kafka → S3/BigQuery/Snowflake pipelines via Kafka Connect S3 Sink or custom Flink jobs for real-time analytics.
Managed Kafka setup with Schema Registry, monitoring, alerting and IAM/SASL authentication wired from day one.
Stack
Apache Kafka 3.8, KRaft, Schema Registry, Kafka Connect, Debezium, ksqlDB, AWS MSK, Confluent Cloud, kafka-go, node-kafka (kafkajs), KEDA, Prometheus Kafka exporter.
Compliance
GDPR-aligned · SOC 2-capable · HIPAA-capable · PCI DSS-aware
Shared: TLS + SASL/SCRAM, Schema Registry BACKWARD compat enforcement, SBOM for client libraries.
Cases
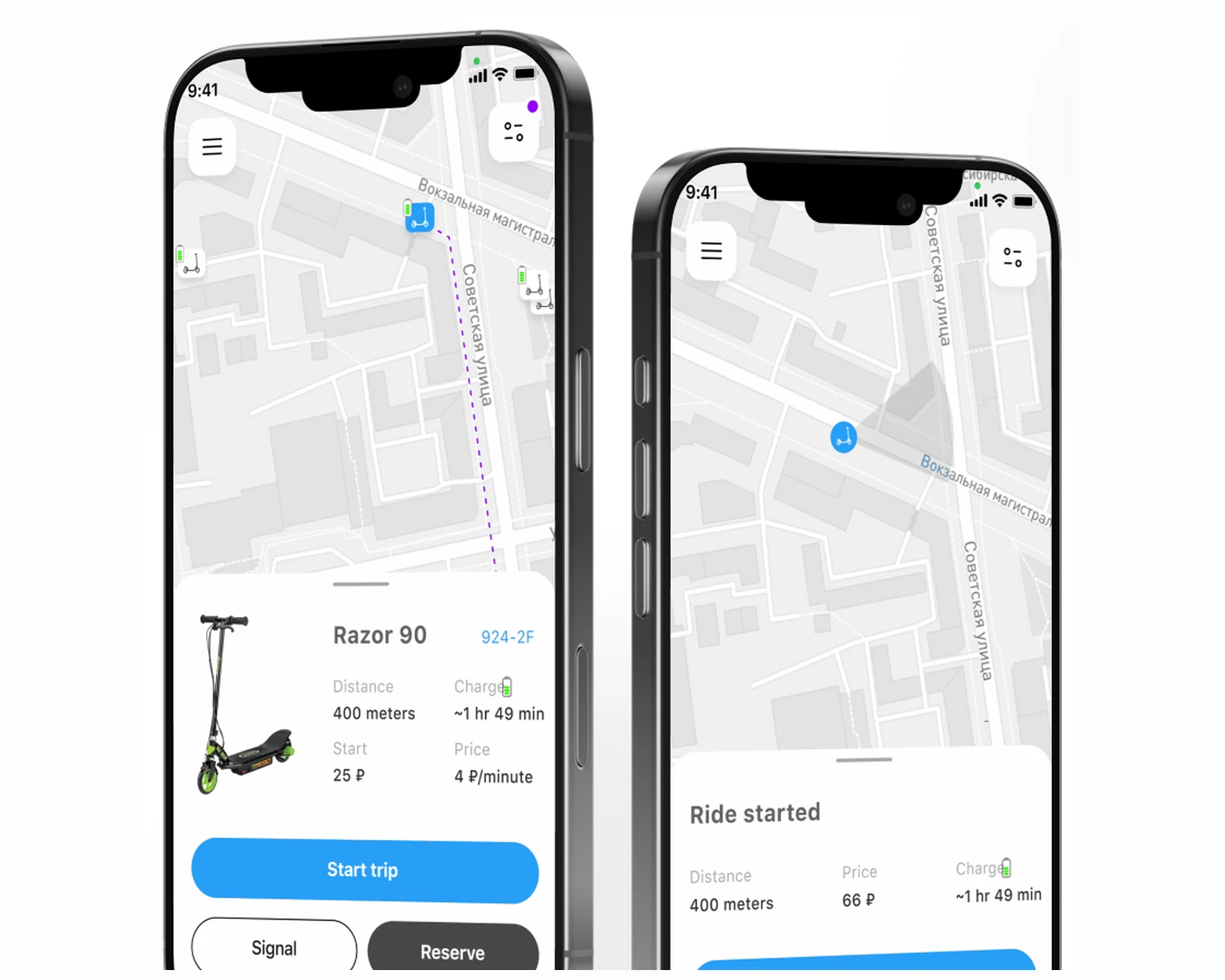
E-scooter sharing app with live map, QR unlock, and ride wallet for iOS and Android — 5,000+ riders, built for US & EU rollouts.
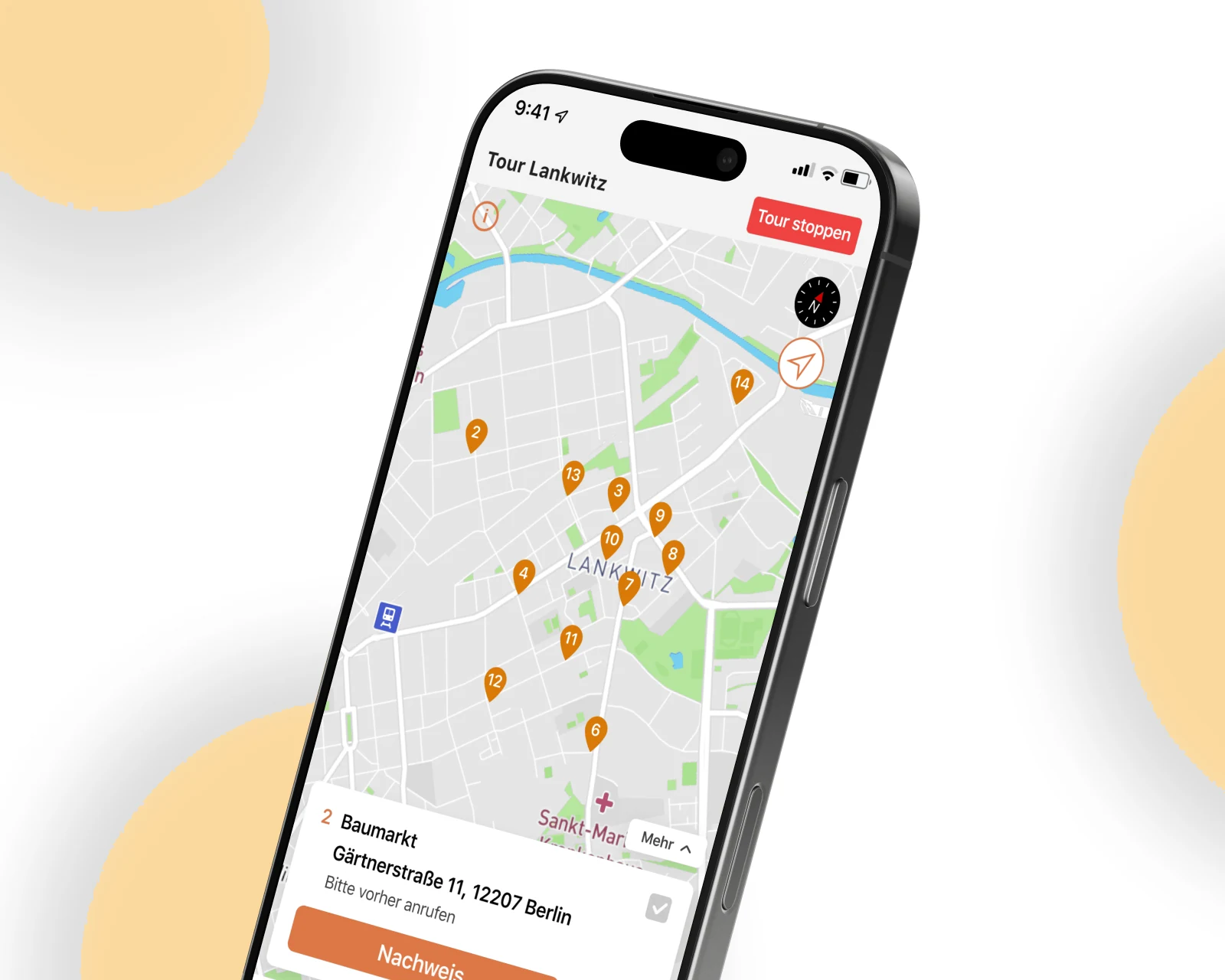
Android + iOS refactor and rebuild for a German last-mile logistics operator — multi-point route planning, real-time driver tracking and in-app invoicing live in the EU.
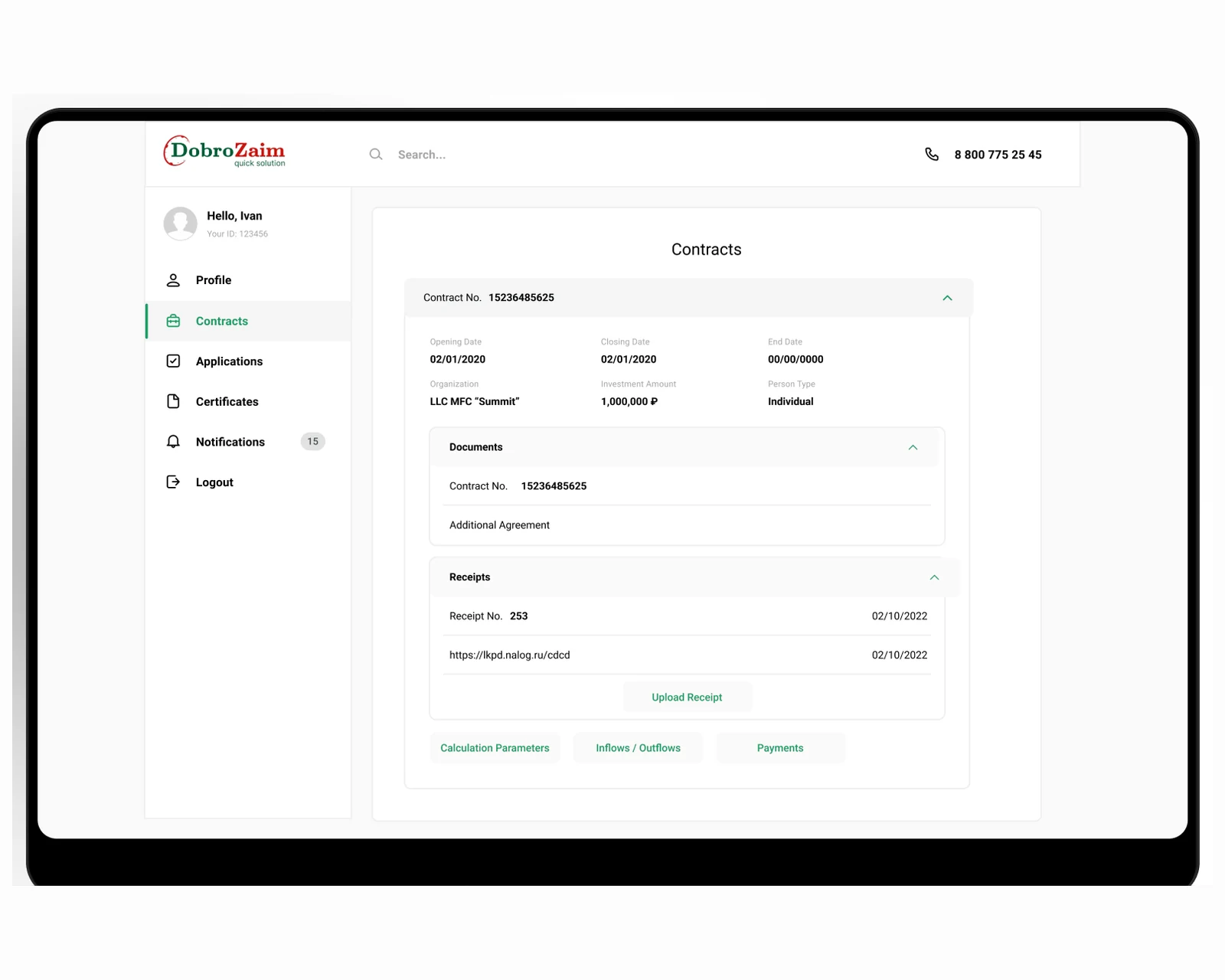
A high-throughput loan decision engine on Laravel — automated scoring, credit-bureau integration, and 10x faster decisions for US & EU lenders.
Why YuSMP
We operate ZooKeeper-free KRaft Kafka clusters — the new standard for new deployments.
Every producer schema change runs a Schema Registry compatibility check in CI before deployment — consumers never see a surprise.
Consumer pods scale to zero between bursts and back to maximum within seconds of queue depth growth — Kafka-native KEDA scalers wired into our standard EKS setup.
FAQ
Kafka for high-throughput multi-consumer pipelines, cross-region replication, long-term message retention and strict ordering within partitions. Redis Streams for lightweight event sourcing within a single data centre where Kafka's operational overhead is not justified. Kafka's compacted topics and schema registry make it the right choice when downstream consumers need schema evolution guarantees.
MSK (Amazon Managed Streaming for Kafka) for teams already on AWS who want to avoid Kafka operational overhead — ZooKeeper replaced by KRaft in recent versions. Confluent Cloud for teams wanting schema registry, ksqlDB and monitoring without managing any Kafka infrastructure. Self-hosted for air-gapped or on-premises environments. We operate all three.
Consumer lag monitoring with the Kafka Consumer Lag Exporter in Prometheus is non-negotiable. We set alerts at 10k message lag for critical topics, implement auto-scaling consumers with KEDA in Kubernetes and design partition counts to match maximum consumer parallelism.
Confluent Schema Registry with BACKWARD compatibility as the default policy — new schema versions must be readable by consumers on the previous version. We enforce schema compatibility checks in CI before deploying producers. FORWARD compatibility for cases where consumers upgrade first.
Kafka transactions (idempotent producer + transactional consumer) for exactly-once within Kafka. For cross-system exactly-once (Kafka → database), we use the outbox pattern: write to a database outbox table in the same transaction as the business operation, and a Kafka Connect Debezium connector reads CDC events from the outbox.
TLS for all broker connections, SASL/SCRAM or mTLS for authentication, ACLs for per-consumer group topic access, and MSK IAM authentication for AWS-managed deployments. Schema registry access controlled per schema subject. We audit Kafka ACLs quarterly.
Response within 1 business day. NDA on request.
Share a few details and a senior consultant will reply within one business day.